Elasticsearch、Logstash、Filebeat、elasticsearch-headでログを見てみた
Tue, Apr 4, 2017
elasticsearch logstash filebeatTable of Contents
NNMiログをFilebeatで集めてLogstashで構造化してElasticsearchに入れてelasticsearch-headで見てみたけど、ログ量が少なかったせいかあんまり恩恵が感じられなかった話。
Elasticsearchとは
ElasticsearchはElastic社が開発しているElastic Stack(旧ELK Stack)というオープンソースなデータ収集分析ツール群のコア製品。 内部でLuceneを使っていて、そのためJava製。 「分散型RESTful検索/分析エンジン」と自称しているが、スキーマレスでNoSQLなドキュメント指向分散データベース管理システムとも見れる。
Elasticsearchインスタンスはノードと呼ばれ、単一または複数のノードによるシステムはクラスタと呼ばれる。 同一ネットワークに複数のノードを立ち上げると自動で相互検出してクラスタを構成してくれ、そこにデータを入れると自動で冗長化して分散配置してくれるので、堅牢でレジリエントでスケーラブルなシステムが簡単に構築できる。
Elasticsearchが管理するデータの最小単位はドキュメントと呼ばれ、これはひとつのJSONオブジェクトで、RDBにおける行にあたる。 つまり、JSONオブジェクトの各フィールドがRDBにおける列にあたる。 同種のドキュメントの集まりはインデックスと呼ばれ、これはRDBにおけるテーブルにあたる。 テーブルのスキーマにあたるものはマッピングと呼ばれ、ドキュメントのフィールドの型情報(e.g. string, integer)などを含み、Elasticsearchが自動で生成してくれる。(指定もできる、というかすべきらしい。) インデックス内ではさらにタイプという属性でドキュメントをカテゴライズできる、が、マニュアルからはタイプはあまり使ってほしくない雰囲気が感じられる。
(2018/4/25追記: 6.0で、一つのインデックスに複数のタイプを作ることができなくなり、7.0では完全にタイプが廃止されることになった。)
因みに、インデックスがRDBのデータベースでタイプがRDBのテーブルと説明されることもあるが、これは古いたとえで、公式が間違いだったとしているので忘れてあげたい。
インデックスは分散処理のために分割でき、分割した各部分はシャードと呼ばれる。 シャードを冗長化のためにコピーしたものはレプリカシャードと呼ばれ、レプリカシャードにより成るインデックスはレプリカと呼ばれる。 デフォルトでは、ひとつのインデックスは5つのシャードに分割され、1つのレプリカが作成される。
インターフェースはREST APIだけ。 REST APIに検索したいドキュメントを投げると、ドキュメントのフィールド毎に自動で形態素解析とかして転置インデックス作って保管してくれる。 検索もJSONで表現したクエリをREST APIに投げることで結果をJSONで受け取ることができる。 検索は転置インデックスや分散処理のおかげで速く、またスコアリングによってより適切な結果が得られるようになっている。
今回使ったのはv5.2.1。
Logstashとは
LogstashはElastic Stackに含まれる製品で、データ収集エンジンであり、データの受け取り、解析/加工、出力の三つの機能を持つリアルタイムパイプラインを構成する。 この三つの機能はそれぞれインプットプラグイン、フィルタプラグイン、アウトプットプラグインで提供されていて、プラグインの組み合わせにより様々なパイプラインを構成できる。
インプットプラグインは単位データ(一回分のログなど)を受け取り、タイムスタンプなどのメタデータを付けたりパースしたりしてイベントを生成し、パイプラインに流す。 フィルタプラグインはインプットプラグインからイベントを受け取り、設定されたルールに従って情報を拡充したり変更したり構造化したり秘匿情報を消したりしてアウトプットプラグインに渡す。 アウトプットプラグインは指定されたディスク上のパスやデータベースやアプリやサービスにイベントを書き込んだり送信したりする。
名前の通りもともとログ収集ツールだったが、今では様々なデータに対応していて、テキストログファイルの他にsyslog、HTTPリクエストやJDBCなんかの入力を受けることもできる。
Ruby(とJava)で書かれている。
今回使ったのはv5.2.2で、プラグインは以下を使った。
- インプット: beats 3.1.12: Beats(後述)からデータを受け取るプラグイン。LumberjackというElastic社が開発しているプロトコルを使い、TCPネットワーク上でデータを受信する。
- フィルタ: grok 3.3.1: 正規表現でパターンマッチして非構造化データを構造化するプラグイン。ログ解析の定番で、例えば、ログからタイムスタンプ、クラス名、ログメッセージを抽出したりする。組み込みのパターンが120個くらいあり、Apache HTTP Serverやsyslogのログであれば自分で正規表現を書く必要はない。
- アウトプット: elasticsearch 6.2.6: Elasticsearchにイベントをポストするプラグイン。
Beatsとは
BeatsもElastic Stackに含まれる製品で、データを採取してLogstashやElasticsearchに送信する製品群の総称。 libbeatというGoのライブラリを使って作られていて、以下のようなものがある。
- Filebeat: ログファイルからログを取得する。
- Heartbeat: リモートサービスをpingして生死監視する。
- Metricbeat: OSとその上のサービスやアプリから稼動情報を取得する。
- Packetbeat: パケットキャプチャしてネットワークのトラフィックを監視する。
- Winlogbeat: Windowsのイベントログを取得する。
今回使ったのはFilebeat 5.2.2。
Filebeatは指定したログファイルを監視し、変更を検知してリアルタイムにログを送信してくれる。 FilebeatとLogstashが仲良くやってくれて、バッファがあふれるなどすることによるログの損失が起きないようにしてくれるらしい。 Logstashが単位データを受け取るので、ログファイルからひとつひとつのログを切り出すのはFilebeatの責務。 一行一ログなら何も考えなくていいけど、大抵複数行のログがあるのでなんとかする必要がある。
elasticsearch-headとは
elasticsearch-headは3rdパーティ製(個人製?)のElasticsearchのWeb UI。 ElasticsearchのUIはREST APIしかないのでこういうものを使わないと辛い。
ElasticsearchのGUIとしてはElastic StackのKibanaが有名だけど、これは大量のログから統計的な情報を見るのに便利そうなものであって、今回やりたかった障害原因調査のためにログを細かく追うのには向いてなさそうだったので使わなかった。
実験環境
今回は単にログがどんな感じに見えるか試したかっただけなので、全部ローカルで動かして、ローカルに置いた静的なログファイルを読むだけ。 環境はWindows 7のノートPC。
ログファイルはC:\Users\Kaito\Desktop\logs\においたnnm-trace.logとnnm-trace.log.1。
これらはNNMiのメインログで、JULで出力されたもの。
NNMiは無料のコミュニティエディションのv10.00をVMのCentOSに適当に入れて採った。
ログはだいたい以下の様な一行のもの。
2017-03-15 19:09:55.896 INFO [com.hp.ov.nms.spi.common.deployment.deployers.ExtensionServicesDeployer] (Thread-2) Deploying arris-device
2017-03-15 19:09:55.923 WARNING [com.hp.ov.nms.topo.spi.server.concurrent.NmsTimerTaskImpl] (NmsWorkManager Scheduler) Skipping task execution because previous execution has not completed: com.hp.ov.nnm.im.NnmIntegrationModule$EnablerTask@3abdac77
2017-03-15 19:09:56.120 INFO [com.hp.ov.nms.disco.spi.DiscoExtensionNotificationListener] (Thread-2) Disco deployed mapping rules: META-INF/disco/rules/cards/ArrisCard.xml
たまに複数行のものがある。
2017-03-15 19:13:30.872 INFO [com.hp.ov.nms.trapd.narrowfilter.NarrowTrapAnalysis] (pool-1-thread-18)
***** Hosted Object Trap Rate Report *****
Hosted object trap storm detection and suppression stage started: Wed Mar 15, 2017 19:09:00.746 PM.
***** General Statistics *****
Hosted Object trap rate threshold: 10 traps/sec.
Average trap rate: 0 traps/sec.
Total traps received: 0.
Total traps received without configuration: 0.
Total traps suppressed: 0.
Number of trap configurations: 1.
***** END Hosted object trap storm report END *****
ログレベルの部分(e.g. INFO、WARNING)はロケールによって日本語になったりする。
スレッド名の部分(e.g. pool-1-thread-18)は丸括弧で囲われているが、丸括弧を含むことがある。
クラス名の部分(e.g. com.hp.ov.nms.trapd.narrowfilter.NarrowTrapAnalysis)は、パッケージ名がついていないこともある。デフォルトパッケージってこともないだろうに。
Elastic Stackのインストールと設定
Elastic Stackの三つはどれも、サイトからアーカイブをダウンロードして展開すればインストール完了。
Filebeatの設定は、展開したディレクトリのトップにあるfilebeat.ymlに以下を書いた。
filebeat.prospectors:
- input_type: log
paths:
- C:\Users\Kaito\Desktop\logs\*
multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}\.[0-9]{3} '
multiline.negate: true
multiline.match: after
output.logstash:
hosts: ["localhost:5043"]pathsでログファイルを指定して、hostsでログの送信先を指定している。
また、複数行のログに対応するため、multilineという設定を書いていて、タイムスタンプで始まらない行は前の行の続きになるようにしている。
Logstashの設定は、展開したディレクトリのトップにpipeline.confというファイルを作ってそこに以下を書いた。
input {
beats {
port => "5043"
}
}
filter {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} (?<log_level>[^ ]+) +\[(?:%{JAVACLASS:class}|(?<class>[A-Za-z0-9_]+))\] \((?<thread>.+(?=\) ))\) (?<log_message>.*)"}
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}inputとoutputの部分は単にbeatsプラグインとelasticsearchプラグイン使うようにして送受信先を指定しているだけ。
filterの部分は、grokプラグインを使うようにしつつそのパターンマッチングを指定している。
FilebeatがJSONオブジェクトのmessageというフィールドに一回分のログを入れて送ってくるので、そこからタイムスタンプ、ログレベル、クラス、スレッド、ログメッセージを抽出し、それぞれtimestamp、log_level、class、thread、log_messageというフィールドに入れるように設定。
TIMESTAMP_ISO8601とJAVACLASSが組み込みのパターンで、それぞれタイムスタンプとJavaのクラス名にマッチする。
けどJAVACLASSがパッケージ名の付いてないクラス名にマッチしないのでちょっと細工している。
Elasticsearchの設定は、展開したディレクトリ内のconfig/elasticsearch.ymlに以下を書いた。
http.cors.enabled: true
http.cors.allow-origin: "*"これは、elasticsearch-headがWebアプリなので、そこからElasticsearchにアクセスできるようにCORSを有効にする設定。
これで設定は終わり。
各製品の起動
Filebeatは普通はサービスとして起動するみたいだけど、今回はコマンドラインで起動する。
展開したディレクトリで以下のコマンドを実行。
filebeat.exe -e -c filebeat.yml -d "publish"Logstashは展開したディレクトリで以下のコマンド。
bin\logstash.bat -f pipeline.confElasticsearchは展開したディレクトリで以下のコマンド。
bin\elasticsearch.batしばらく待つと起動完了し、localhost:9200でHTTPリクエストを待ち始める。
試しにブラウザでhttp://localhost:9200/_cluster/healthにアクセスすると、以下の様にElasticsearchクラスタのステータスがJSONで返ってきた。
{"cluster_name":"elasticsearch","status":"yellow","timed_out":false,"number_of_nodes":1,"number_of_data_nodes":1,"active_primary_shards":5,"active_shards":5,"relocating_shards":0,"initializing_shards":0,"unassigned_shards":5,"delayed_unassigned_shards":0,"number_of_pending_tasks":0,"number_of_in_flight_fetch":0,"task_max_waiting_in_queue_millis":0,"active_shards_percent_as_number":50.0}以上でElastic Stackが起動し、Elasticsearchにログが読み込まれた。
elasticsearch-headでログを見る
elasticsearch-headはgit clone https://github.com/mobz/elasticsearch-head.gitしてその中のindex.htmlをブラウザで開けば動く。組み込みのWebサーバを起動する手順もあるけど。
開くとhttp://localhost:9200/(i.e. Elasticsearch)にアクセスしてGUIに情報を表示してくれる。
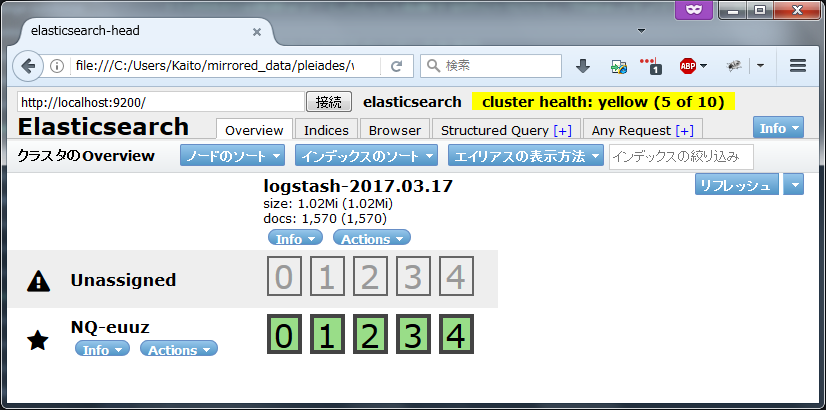
Overviewタブには以下の様に、logstash-2017.03.17というインデックスが作られていて、それに対して5つのシャードとレプリカシャードが作られている様が表示される。
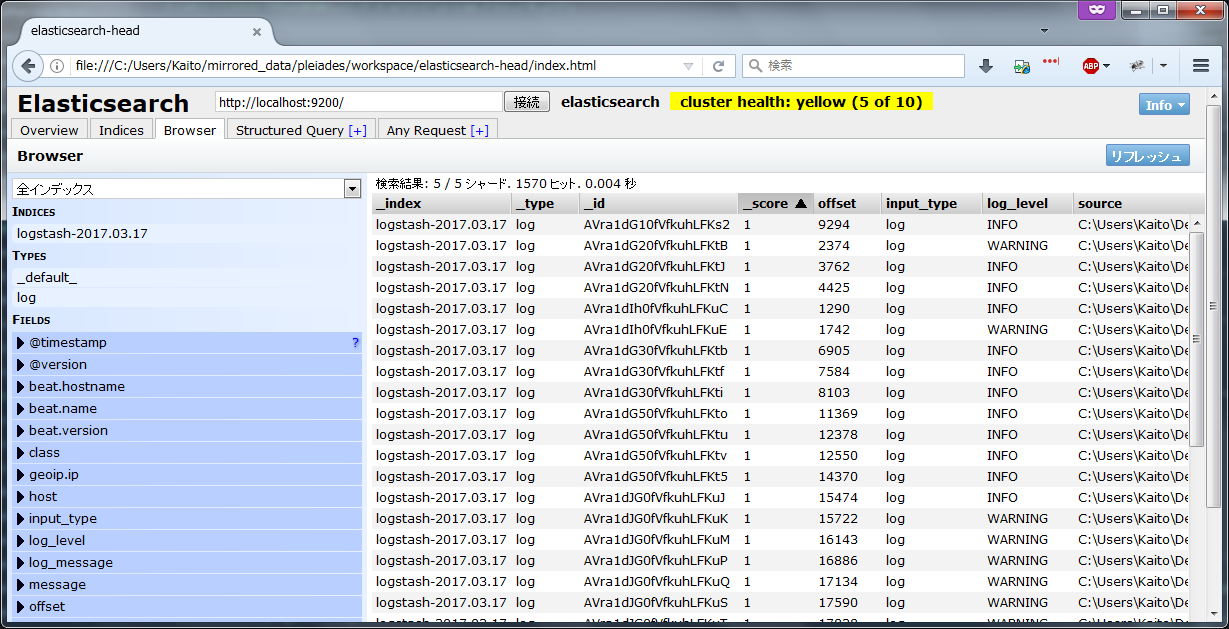
Browserタブではざっくりとログの一覧が見れる。
Structured Queryタブでは条件を指定してログを表示できる。
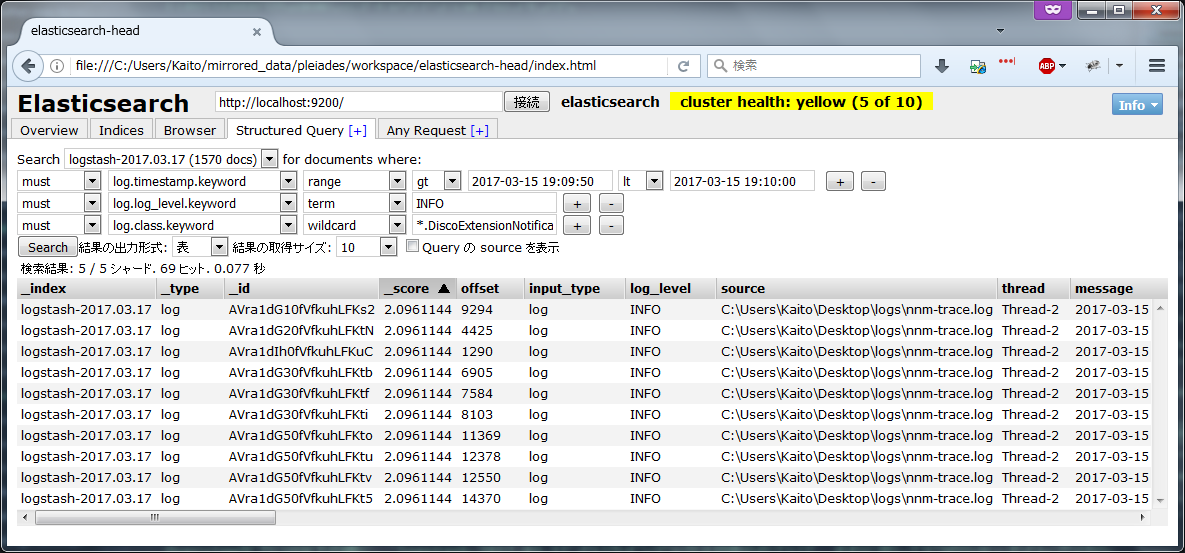
ここでは2017/3/15 19:09:50から2017/3/15 19:10:00の間のINFOレベルのDiscoExtensionNotificationListenerクラスのログを10件表示した。
不要な列を非表示にできないし、ソートもできないし、ログメッセージ見難くくて全く使えない。 もう少しいいGUIがあれば使えるのか、そもそもElasticsearchを使うのが間違っているのか。