
Table of Contents
SQLAlchemyを使ってPythonでORMしたかったけど、そこまでたどり着かなかった記事。
この記事でSQLAlchemy Coreについて要点をおさえておいて、次回の記事でSQLAlchemy ORMに手を出す。
ORMとは
ORMはObject-relational mappingの略で、和訳するとオブジェクト関係マッピング。 関係というのは関係データベース(RDB)のこと。
ORMは、RDBのレコードをプログラミング言語におけるオブジェクトとして扱う技術。 大抵は、オブジェクト指向なプログラミング言語で、1つのクラスでRDBの1テーブルを表現して、そのクラスのインスタンスでそのテーブルのレコードを表現する。 クラスの各メンバフィールドをテーブルの各カラムに対応させることで、1インスタンスで1レコードのデータを保持できる。
ORMライブラリ
ORMは原始的には、プログラミング言語が提供するAPIでRDBにつないでSQLでレコードを取得して、各カラムの値を取り出して型を整えて、その値を使って対応するクラスをインスタンス化するなどすれば実現できる。 けどそれを全部自前でやるのは辛いので、助けてくれるライブラリが各プログラミング言語にある。
そのようなORMライブラリは大抵以下のような機能を提供してくれる。
- RDBMSの種類の違いによるAPIの差異を抽象化して、コネクションやトランザクションを扱いやすくする。
- SQL文をプログラミング言語の特性を活かして流暢に書けるようにする。
- クラスとテーブルを関連付けて、SQLクエリの結果をオブジェクトに変換したり、オブジェクトへの操作からSQLを自動発行してくれたりする。
SQLAlchemy
PythonのORMライブラリで一番メジャーなのがSQLAlchemy。 JavaのHibernateなどのORMライブラリとは違って、RDBやSQLをあまり隠蔽せず、開発者がコントロールできるようになっているのが特徴的な設計思想。
SQLAlchemyは大きく以下の二つのコンポーネントからなる。
-
PythonのDBAPIを抽象化して、前節の#1と#2の機能を実現する。
-
Coreの上で作られていて、前節の#3の機能を実現する。 テーブルと関連付けられたクラスから作られたインスタンスは普通のPythonオブジェクトとして扱えて、pickleでシリアライズとかしてもいい。 継承関係にあるクラスをテーブルにマッピングすることもできる。
SQLAlchemy Core
最終的に使いたいのはSQLAlchemy ORMの方なんだけど、SQLAlchemy ORMはSQLAlchemy Coreの上に作られたコンポーネントなので、この記事ではとりあえずCoreについて見ていく。
主要なオブジェクト
Coreの機能を理解するうえで押さえておきたいオブジェクトは以下
-
SQLAlchemyの使用は、まず
create_engine()でEngineオブジェクトを作ることから始まる。 Engineは、RDBとのコネクションを張るための設定やコネクションプールを管理するオブジェクトで、基本は1アプリで1つだけインスタンス化する。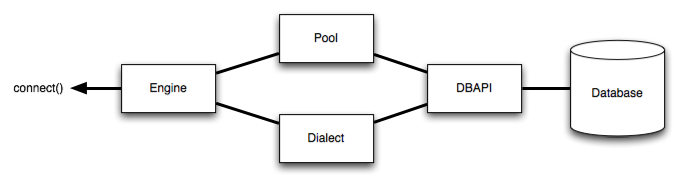
Engineオブジェクトの
connect()を呼んだり、後述のexecute()などのRDBコネクションが必要なメソッドを呼ぶと、RDBとのDBAPIコネクションが張られて、コネクションプールで管理される。 コネクションプールは上図のPoolというオブジェクトで表されるもので、Engineが内部に一つ持つ。 Poolはデフォルトで5~10個のコネクションを保持する。上図のDialectはRDBMSのRDBMSの種類の違いによるAPIの差異を抽象化してくれるオブジェクトだけど、あまり気にしなくていい。
-
Engine(というかPool)によってRDBとのDBAPIコネクションが張られると、Connectionというオブジェクトでラップされ、Poolに入れられる。 Connectionは使い終わったらcloseするんだけど、closeしてもConnectionオブジェクトが破棄されたりDBAPIコネクションが切れわけではなく、ConnectionオブジェクトはPoolに返されて、DBAPIコネクションはクリーンアップされて再利用される。
Connectionはスレッドセーフではないしスレッド間で共有される想定の作りではないので、スレッドごとに取得するものと考えておけばいい。
-
Connectionの
begin()を呼ぶとトランザクションが始まり、それを扱うTransactionオブジェクトが作られる。 トランザクションはTransactionのcommit()かrollback()を呼ぶと終わらせられる。
SQLAlchemy CoreでのSQL文実行
上記オブジェクトを組み合わせて、SQL文を実行する最も率直な例は以下:
from sqlalchemy import create_engine
# Engineのインスタンスを作る。Poolも作られる。
engine = create_engine("postgresql://admin:passwd@localhost/test_db")
# PoolがDBAPIを使ってRDBとのコネクションを張り、Connectionオブジェクトに入れて返してくれる。
connection = engine.connect()
# トランザクションを開始。Transactionオブジェクトが返される。
transaction = connection.begin()
connection.execute("insert into hoge (a, b) values (1, 2)")
# RDBへの操作をコミット。トランザクションが修了する。
transaction.commit()
# ConnectionがPoolに返される。
connection.close()これはこれで動くけど、普通はこうは書かない。
Connectionはコンテキストマネージャでもあるので、with文で受けることでclose()を自動実行できる。
with文を使うやり方の方がclose()の実行が保証されるので推奨される。
同様にTransactionもコンテキストマネージャなので、with文で受けてcommit()(またはrollback())を自動実行できる。
from sqlalchemy import create_engine
engine = create_engine("postgresql://admin:passwd@localhost/test_db")
with engine.connect() as connection:
with connection.begin():
connection.execute("insert into hoge (a, b) values (1, 2)")さらに、Engine.connect()とConnection.begin()を同時にできるEngine.begin()を使うと、以下のようにかなり簡単に書くこともできる。
from sqlalchemy import create_engine
engine = create_engine("postgresql://admin:passwd@localhost/test_db")
with engine.begin() as connection:
connection.execute("insert into hoge (a, b) values (1, 2)")因みに、engine.execute("select * from hoge")みたいにConnectionもTransactionもすっとばしてSQL文を実行するConnectionless Executionという機能もあるけど、これは今は非推奨なので忘れるべし。
以降、ConnectionやTransactionについて留意したいことについて書いておく。
トランザクションの管理
前節に書いたように、SQLAlchemyではユーザが明示的にトランザクションの開始と修了を管理する必要があるんだけど、SQLAlchemyを使ってDAO的なモジュールを作っていると、トランザクション管理をDAOの関数内ですべきか、DAOを使う側ですべきかちょっと迷うかもしれない。 DAOの関数内でやると、DAOを使う側でトランザクションを処理しなくていいので楽だけど、トランザクションの範囲はデータをどう処理したいかによって変わるので、現実的にはDAOを使う側で管理したくなることも多い。
(多分)そんな悩みを解消するため、SQLAlchemyではトランザクションのネストがサポートされている。
ネストというのは、以下のようにwith connection.begin()で開始したトランザクションのなかで、再度with connection.begin()するようなやつ。
# DAO的な関数
def add_hoge(a, b, connection):
with connection.begin(): # 子トランザクション
connection.execute(f"insert into hoge (a, b) values ({a}, {b})")
# DAOを使う側の関数
def main():
with engine.connect() as connection:
with connection.begin(): # 親トランザクション
add_hoge(1, 2, connection)
add_hoge(10, 20, connection)add_hoge()は中でトランザクションを持つので、単体で呼べば期待した通りにレコードをinsertしてコミットしてくれる。
一方、main()でやっているようにadd_hoge()をトランザクションで囲んでやると、add_hoge()内のconnection.begin()ではトランザクションは開始されず、コミットもされない。
これは便利と思いきや、本格的なプロジェクトでトランザクションのネストを使うと複雑になり過ぎて、トランザクションの範囲が分かりにくくなる弊害があるらしく、次バージョンのv1.4からは非推奨になるのでやらないほうがいい。
今後は以下のようにDAOの外だけでトランザクションを管理すべし。
# DAO的な関数
def add_hoge(a, b, connection):
connection.execute(f"insert into hoge (a, b) values ({a}, {b})")
# DAOを使う側の関数
def main():
with engine.connect() as connection:
with connection.begin(): # トランザクション
add_hoge(1, 2, connection)
add_hoge(10, 20, connection)コネクションプールとプロセスフォーク
上の方で、基本的に一つのPythonアプリでは一つのEngineをインスタンス化するというのを書いたけど、それはつまりコネクションプールを一つにするということ。 SQLAlchemyは必要に応じてDBAPIコネクションを作ってコネクションプールに保持させるわけだけど、それは具体的にはRDBMSと通信するためのソケットファイルを扱うファイルディスクリプタを保持させるということになる。
ということは、並列処理とかをするためにPythonプロセスをフォークして、Engineインスタンスとコネクションプールがコピーされると、同じファイルディスクリプタを複数のプロセスで持つことになる。
それぞれのプロセスで同じファイルディスクリプタを読み書きすると当然問題になるので、フォークしたプロセスでは一旦Engineのdispose()を呼んでコネクションプールを作り直さないといけない。
DBAPIコネクションの切断
Connectionは、使うときはコネクションプールから取得して、使い終わったらclose()してコネクションプールに返すんだけど、そのときDBAPIコネクションが切断されるというわけではないよというのを上の方で書いた。
しかしそれはDBAPIコネクションがずっと繋がりっぱなしという意味ではない。
RDBMS側でタイムアウトなどの理由で切ってくることもあるし、RDBMSが再起動したらプール内のコネクションは全部切れる。
DBAPIコネクションが切れた時、コネクションプールは何をしてくれるかというと、デフォルトではあんまり何もしてくれない。 つながっていないConnectionをしれっと渡してくるので、アプリ側でそれを使うとエラーになる。 一旦アプリ側でエラーを起こしてやると、コネクションプールが切断に気づいてくれて、そのConnectionとそれ以前のものを再接続してくれはする。
これはこれで、アプリ側で気をつけてエラー処理やリトライしてやればなんとかなるんだけど、もうちょっとコネクションプールに頑張って欲しい場合は、以下の二つの機能が有効。
-
Trueにしておくと、コネクションプールからConnectionを返す前に、RDBMSにping(SELECT 1的なやつ)を放ってDBAPIコネクションが生きているかを確認してくれる。切れてたらつないでからConnectionを返してくれる。性能に若干影響が出る。
-
秒数を指定しておくと、コネクションプールからConnectionを返す前に、DBAPIコネクションがその秒数より古かったら新たに繋ぎなおしてからConnectionを返してくれる。
RDBMS側のタイムアウトに合わせて設定しないとあまり機能しないのと、RDBMSの再起動に対しては無力。 なので基本はアプリ側のリトライと組み合わせて使う。
上記の機能はいずれかを設定しておけば安定性が増していい感じだけど、コネクションプールからConnectionを取得するタイミングでしか働かないことには注意すべし。
アプリ側で使っている最中にConnectionのDBAPIコネクションが切れたりしても、コネクションプールは何もしてくれない。
コネクションプールがConnectionやDBAPIコネクションを適切に管理できるようにするためには、こまめにConnectionをclose()してプールに返してやることが重要。
SQLAlchemy ORMについては次回の記事で。