機械学習のHello World: MNISTの分類モデルをKerasで作ってみた
Sun, Mar 25, 2018
machine learning deep learning neural network tensorflow keras
Table of Contents
機械学習のHello WorldとしてよくやられるMNISTの分類モデルをKeras on TensorFlowで作ってみた話。
MNISTとは
手書き数字画像のラベル付きデータセット。 6万個の訓練データと1万個のテストデータからなる。 CC BY-SA 3.0で配布されているっぽい。
一つの画像は28×28ピクセルの白黒画像で、0から9のアラビア数字が書かれている。
画像とラベルがそれぞれ独特な形式でアーカイブされていて、画像一つ、ラベル一つ取り出すのも一苦労する。
Kerasとは
Pythonのニューラルネットワークライブラリ。 バックエンドとしてTensorFlowかCNTKかTheanoを使う。 今回はTensorFlowを使った。
やったこと
KerasのMNISTのAPIとかコードサンプルとかがあけどこれらはスルー。
MNISTのサイトにあるデータセットをダウンロードしてきて、サイトに書いてあるデータ形式の説明を見ながらサンプルを取り出すコードを書いた。 で、KerasでVGGっぽいCNNを書いて、学習させてモデルをダンプして、ダンプしたモデルをロードしてテストデータで評価するコードを書いた。 コードはGitHubに。
ネットワークアーキテクチャ
入力画像のサイズに合わせてVGGを小さくした感じのCNNを作った。
VGGは2014年に発表されたアーキテクチャで、各層に同じフィルタを使い、フィルタ数を線形増加させるシンプルな構造でありながら、性能がよく、今でもよく使われるっぽい。
VGGを図にすると以下の構造。
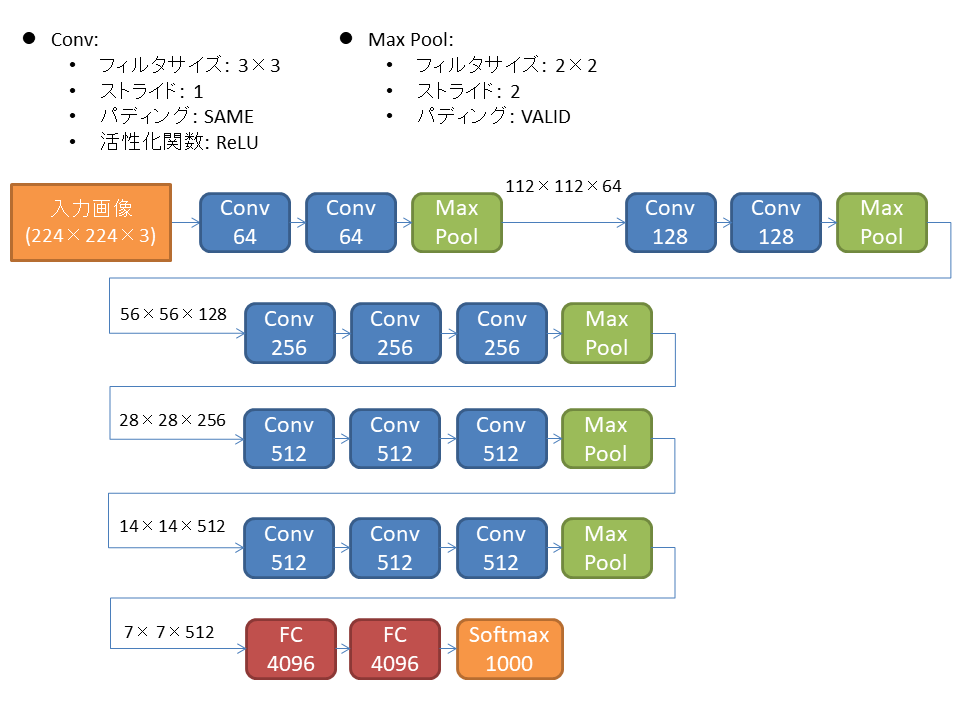
実際はバッチ正規化とかDropoutもやるのかも。 プーリング層は数えないで16層なので、VGG-16とも呼ばれる。 パラメータ数は1億3800万個くらいで、結構深めなアーキテクチャ。
VGG-16は244×244×3の画像を入力して1000クラスに分類するのに対し、MNISTは28×28×1を入れて10クラスに分類するので、以下のような7層版を作った。
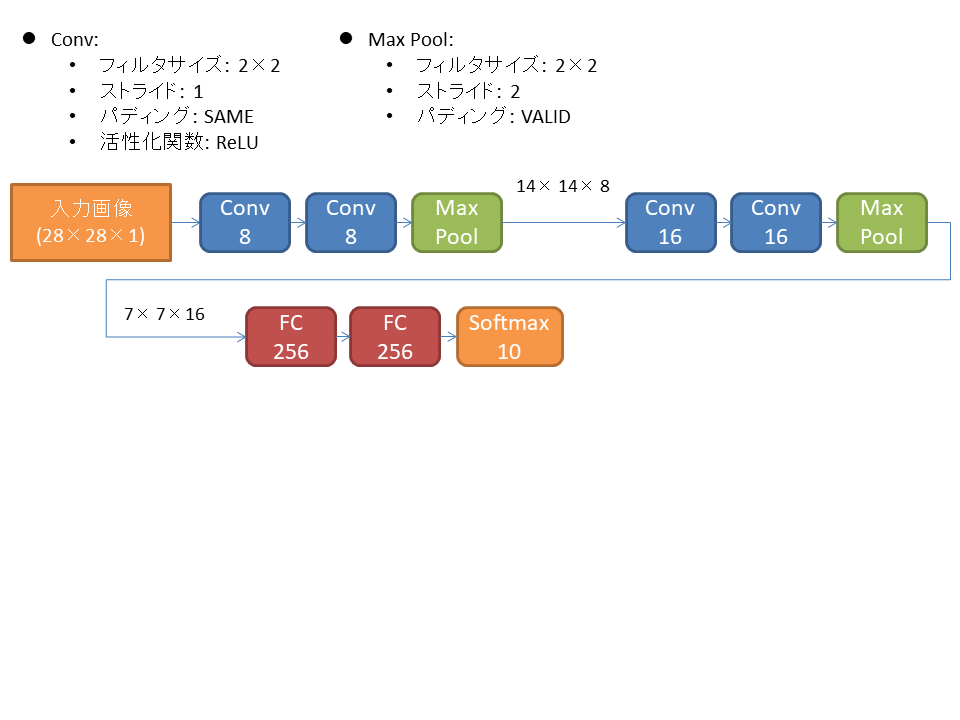
これでパラメータ数は27万個くらい。 訓練データのサンプル数が6万個なので、パラメータ数が大分多い感じではある。
コードは以下。
inputs: Tensor = Input(shape=(IMAGE_NUM_ROWS, IMAGE_NUM_COLS, 1))
x: Tensor = Conv2D(filters=8, kernel_size=(2, 2), padding='same', activation='relu')(inputs)
x = Conv2D(filters=8, kernel_size=(2, 2), padding='same', activation='relu')(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Conv2D(filters=16, kernel_size=(2, 2), padding='same', activation='relu')(x)
x = Conv2D(filters=16, kernel_size=(2, 2), padding='same', activation='relu')(x)
x = Conv2D(filters=16, kernel_size=(2, 2), padding='same', activation='relu')(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Flatten()(x)
x = Dense(units=256, activation='relu')(x)
x = Dense(units=256, activation='relu')(x)
predictions: Tensor = Dense(NUM_CLASSES, activation='softmax')(x)
model: Model = Model(inputs=inputs, outputs=predictions)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])訓練・評価
上記モデルを6万個のサンプルでバッチサイズ512で一周(1エポック)学習させると、Intel Core i5-6300HQプロセッサー、メモリ16GBのノートPCで28秒前後かかる。
とりあえず3エポック学習させてみる。
(ml-mnist) C:\workspace\ml-mnist>python bin\ml_mnist.py train
Using TensorFlow backend.
Epoch 1/3
60000/60000 [==============================] - 28s 465us/step - loss: 0.7813 - acc: 0.7702
Epoch 2/3
60000/60000 [==============================] - 27s 453us/step - loss: 0.1607 - acc: 0.9496
Epoch 3/3
60000/60000 [==============================] - 27s 448us/step - loss: 0.1041 - acc: 0.9681ロスが0.1041で正答率が96.81%という結果になった。
このモデルをテストデータで評価する。
(ml-mnist) C:\workspace\ml-mnist>python bin\ml_mnist.py eval
Using TensorFlow backend.
10000/10000 [==============================] - 2s 165us/step
loss: 0.08780829641819, acc: 0.9717000002861023正答率97.17%。 そんなに良くないけど、過学習はしていない模様。
次に10エポック学習させて評価してみる。
(ml-mnist) C:\workspace\ml-mnist>python bin\ml_mnist.py train
Using TensorFlow backend.
Epoch 1/10
60000/60000 [==============================] - 29s 486us/step - loss: 0.5814 - acc: 0.8297
Epoch 2/10
60000/60000 [==============================] - 28s 470us/step - loss: 0.1130 - acc: 0.9651
Epoch 3/10
60000/60000 [==============================] - 28s 469us/step - loss: 0.0711 - acc: 0.9777
Epoch 4/10
60000/60000 [==============================] - 28s 468us/step - loss: 0.0561 - acc: 0.9821
Epoch 5/10
60000/60000 [==============================] - 28s 469us/step - loss: 0.0476 - acc: 0.9852
Epoch 6/10
60000/60000 [==============================] - 28s 473us/step - loss: 0.0399 - acc: 0.9879
Epoch 7/10
60000/60000 [==============================] - 28s 467us/step - loss: 0.0338 - acc: 0.9892
Epoch 8/10
60000/60000 [==============================] - 28s 467us/step - loss: 0.0283 - acc: 0.9909
Epoch 9/10
60000/60000 [==============================] - 29s 490us/step - loss: 0.0230 - acc: 0.9925
Epoch 10/10
60000/60000 [==============================] - 28s 471us/step - loss: 0.0223 - acc: 0.9928
(ml-mnist) C:\workspace\ml-mnist>python bin\ml_mnist.py eval
Using TensorFlow backend.
10000/10000 [==============================] - 2s 171us/step
loss: 0.040611953073740006, acc: 0.9866999998092651テストデータでの正答率98.67%。 ちょっと改善した。
モデル改善
試しにバッチ正規化層を入れてみる。 ReLUの前に入れるべきという情報があったけど、それだとちょっと修正が面倒なので、単にプーリング層の後に入れてみた。
3エポックで学習・評価。
(ml-mnist) C:\workspace\ml-mnist>python bin\ml_mnist.py train
Using TensorFlow backend.
Epoch 1/3
60000/60000 [==============================] - 45s 746us/step - loss: 0.2157 - acc: 0.9336
Epoch 2/3
60000/60000 [==============================] - 44s 737us/step - loss: 0.0513 - acc: 0.9838
Epoch 3/3
60000/60000 [==============================] - 47s 777us/step - loss: 0.0340 - acc: 0.9896
(ml-mnist) C:\workspace\ml-mnist>python bin\ml_mnist.py eval
Using TensorFlow backend.
10000/10000 [==============================] - 2s 246us/step
loss: 0.051704482543468475, acc: 0.984499999523162898.45%。 1エポックの学習時間は45秒前後に伸びたけど、速く学習できるようにはなった。
10エポックではどうか。
(ml-mnist) C:\workspace\ml-mnist>python bin\ml_mnist.py train
Using TensorFlow backend.
Epoch 1/10
60000/60000 [==============================] - 47s 776us/step - loss: 0.2318 - acc: 0.9265
Epoch 2/10
60000/60000 [==============================] - 47s 790us/step - loss: 0.0596 - acc: 0.9811
Epoch 3/10
60000/60000 [==============================] - 47s 778us/step - loss: 0.0370 - acc: 0.9884
Epoch 4/10
60000/60000 [==============================] - 48s 801us/step - loss: 0.0259 - acc: 0.9917
Epoch 5/10
60000/60000 [==============================] - 47s 785us/step - loss: 0.0182 - acc: 0.9942
Epoch 6/10
60000/60000 [==============================] - 48s 794us/step - loss: 0.0132 - acc: 0.9961
Epoch 7/10
60000/60000 [==============================] - 46s 765us/step - loss: 0.0108 - acc: 0.9965
Epoch 8/10
60000/60000 [==============================] - 45s 751us/step - loss: 0.0107 - acc: 0.9965
Epoch 9/10
60000/60000 [==============================] - 45s 749us/step - loss: 0.0055 - acc: 0.9984
Epoch 10/10
60000/60000 [==============================] - 45s 754us/step - loss: 0.0035 - acc: 0.9991
(ml-mnist) C:\workspace\ml-mnist>python bin\ml_mnist.py eval
Using TensorFlow backend.
10000/10000 [==============================] - 2s 243us/step
loss: 0.034382903814315795, acc: 0.989399999427795498.94%。 バッチ正規化無し版よりも0.27%改善してるけど、誤差の範囲かも。
MNISTのサイトに載ってるので一番いいのが99.77%。 どうしたらそんなによくなるのか。
エラー分析
一番正答率が高かったモデルについて、エラー分析をしてみた。
まず、エラーが多かった数字を調べる。 数字をエラー数順に並べると、
ラベル: エラー数
9: 18
7: 18
5: 15
4: 14
6: 14
3: 8
8: 8
2: 7
1: 2
0: 29と7が一番分類むずくて、4、5、6がそれらに次いでむずいことがわかる。
次にエラーのパターンを見てみる。
(予測した数字, ラベル): 出現数
(9, 4): 10
(3, 5): 9
(1, 7): 7
(2, 7): 6
(7, 9): 6
(9, 7): 5
(7, 2): 4
(8, 5): 4
(1, 6): 4
(1, 9): 4
(0, 6): 4
(8, 9): 3
(9, 3): 3
(4, 9): 3
(8, 3): 2
(2, 4): 2
(2, 8): 2
(1, 2): 2
(8, 4): 2
(5, 3): 2
(5, 9): 2
(8, 6): 2
(2, 6): 2
(5, 6): 1
(1, 8): 1
(6, 8): 1
(0, 8): 1
(2, 3): 1
(4, 6): 1
(2, 1): 1
(3, 8): 1
(8, 1): 1
(7, 0): 1
(4, 8): 1
(6, 0): 1
(5, 8): 1
(6, 5): 1
(9, 2): 1
(0, 5): 14を9と、5を3と、7を1か2と、9を7と間違えたパターンが多い。 特に4と7がむずい模様。
次に、実際に間違えた画像を見てみる。 多かったパターンについて見てみる。
4を9と間違えたパターン:

なんだこれは。 これはかなり9にも見える。 ちょっと角ばってるとこと、線が右にはみ出しているとこで判断するのか。
5を3と間違えたパターン:
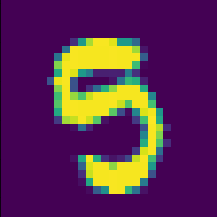
これはもうちょっとモデルに頑張ってほしい。 これを3としてしまうのは残念。 なにがだめだったのかは分からないけど。
7を1と間違えたパターン:
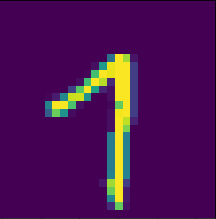
これは1でもいいような…
7を2と間違えたパターン:
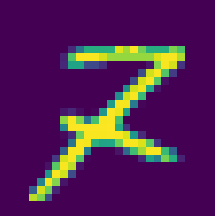
これはちょっと面白い。 7の真ん中に線をいれるパターンを訓練データに足せば対応できそう。
9を7と間違えたパターン:
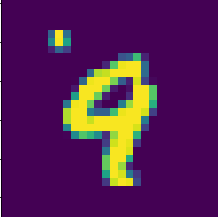
これもモデルに頑張ってほしかったパターン。 左上のごみが悪さしたんだろうか。 ごみがあるパターンを訓練データに増やすと対応できるかも。
あと、ちょっと噴いたやつ:
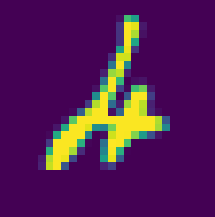
これは4。 モデルは2と間違えた。 むずい。
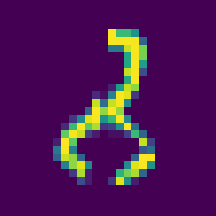
これは8。 モデルは2と間違えた。 こんなのテストデータにいれないで…