Admiraltyのvirtual-kubeletでKubernetesクラスタからk3sにPodをオフロードする
Thu, Dec 9, 2021
Kubernetes k3s virtual-kubelet admiralty
Table of Contents
KubernetesクラスタにAdmiraltyのvirtual-kubeletでk3sクラスタを仮想ノードとしてつなげてみた話。
なおこれは、QiitaのKubernetes Advent Calendar 2021の9日目の記事である。
virtual-kubeletとは
virtual-kubeletはkubeletのAPIを実装したもの。
普通のkubeletがKubernetesクラスタにコンテナランタイムを乗せた1マシンを1ノードとして追加するのに対して、virtual-kubeletは別の何かを1ノードとして追加し、ノードとして振舞わせる。 ノードの役割はPodを実行することなので、virtual-kubeletはつまり普通の1マシン以外の環境でPodを実行するために使われる。
virtual-kubeletはプラガブルなアーキテクチャになっていて、providerを変えることでPodを実行する環境を変えることができる。 providerには、PodをAWS Fargateで実行するものとか、Azure Container Instancesで実行するものとかがあるが、この記事では、別のKubernetesクラスタで実行するAdmiraltyを試す。
Admiraltyの仕組み
Admiraltyは、Kubernetesクラスタのノードとして別のKubernetesクラスタを接続する。 前者はソースクラスタ、後者はターゲットクラスタ、ソースクラスタにAdmiraltyが作るノードは仮想ノードと呼ばれ、仮想ノードにスケジューリングされたPodがターゲットクラスタのいずれかのノードで実行される。
Admiraltyの仕組みは以下のシーケンス図を見るとわかりやすい。

図で、白文字のアクタがPodとして起動されるAdmiraltyのデーモンで、青文字のアクタがKubernetesのリソース。 Kubernetesリソースは色々あるように見えるけど、PodChaperonだけがカスタムリソースで、他は役割が違うだけの普通のPod。
まず、DeploymentとかJobとかの登録とかを契機に、Podを登録するリクエストがソースクラスタのkube-apiserverに投げられたとする。 このPodが図中でSource Podと書かれているもの。 この時点では全く普通のPod。
kube-apiserverは、そのPodを登録する前に、ソースクラスタで動いているMutating Pod Admission WebhookにそのPodを投げる。 その後そのkube-apiserverは、Mutating Pod Admission Webhookが編集したPodをレスポンスで受け取り、登録する。 この登録されるPodは図中でProxy Podと書かれているもので、以下のようなもの。
- 仮想ノードにスケジュールされて、ターゲットノードで実際に実行されるPodのstatusをミラーする。
- アノテーションの
multicluster.admiralty.io/sourcepod-manifestにもとのPodが入っている。 - 仮想ノードにスケジュールされるように、以下のように編集されている。
- nodeSelectorに
virtual-kubelet.io/provider: admiraltyが設定されている。 - tolerationsに
virtual-kubelet.io/provider: admiraltyに対する許容が設定されている。(virtual-kubelet.io/provider: admiraltyはAdmiraltyによる仮想ノードに付くtaint。) - affinityとtopologySpreadConstraintsが削除されている。
- nodeSelectorに
- schedulerNameに
admiralty-proxyが設定され、下記Proxy Schedulerで処理されるようになっている。
Proxy Podがソースクラスタに登録されると、そのschedulerNameの指定に従ってProxy Schedulerが読み取り、全ターゲットクラスタにPodChaperonを登録する。 PodChaperonは以下のようなもの。
- 型は普通のPodと同じ。
- Proxy Podのアノテーションの
multicluster.admiralty.io/sourcepod-manifestの値を基に、Source Podと同様のspecを表現する。 - schedulerNameに
admiralty-candidateが設定されている。 - Proxy Podと後述のCandidate Podとの間の中間オブジェクト。
- Podに似ているけどPodではないので、スケジューラやkubeletには処理されない。
PodChaperonが登録されると、それぞれのターゲットクラスタのPod Chaperon Controllerがそれを読み取り、同じspecでPodを登録する。 このPodが図中のCandidate Pod。 Podではあるけど、この時点ではまだ名前の通り候補に過ぎず、ノードにスケジューリングされていないので、コンテナは実行されない。 スケジューリングは、schedulerNameで指定されたCandidate Schedulerが実行する。
Candidate SchedulerはCandidate Podに対し、通常のスケジューラのように、ノードの空きリソース、Podの要求リソース、Podのaffinityとかをみて割り当てるノードを決める。
ただし通常のスケジューラとは違い、Candidate Podに実際にノードを割り当てる(i.e. nodeNameにノード名を入れる)ことはせず、代わりに対応するPodChaperonにアノテーションとしてmulticluster.admiralty.io/is-reserved: trueを設定する。
ソースクラスタのProxy Schedulerは、multicluster.admiralty.io/is-reserved: trueが付いたPodChaperonのなかからひとつ選んで、アノテーションにmulticluster.admiralty.io/is-allowed: "true"を付け、ひとつのCandidate SchedulerにPodの実行を許可する。
許可されたCandidate Schedulerは、そのPodChaperonに対応するCandidate PodのnodeNameを入れて、実際にノードに割り当てる。 この段階でこのCandidate Podはもう「候補」ではないので、Delegate Podと呼ばれるものになり、Source Podの代わりにコンテナを実行する。
コンテナが実行されると、Delegate Podのstatusが更新されていくが、これはPod Chaperon Controllerによって対応するPodChaperonのstatusに反映され、さらに(図に書かれてないけどソースクラスタで動いているFeedback Controllerによって)Proxy Podのstatusに反映される。
Proxy Schedulerは、PodChaperonのstatusを見て、無事Delegate Podが実行開始したのを見届けたら、他のPodChaperonを削除する。 Pod Chaperon Controllerは、PodChaperonが削除されたら対応するCandidate Podを削除する。
以上のような感じでターゲットクラスタでPodが実行される。 なんでソースクラスタのコントローラでターゲットクラスタのPodを直接触らないで、PodChaperonを介しているかというと、PodChaperonを境にソースクラスタとターゲットクラスタの責務を分離するためらしい。 つまり、実際にコンテナを起動し得るPodをいじるのは、そのPodがいるクラスタのコントローラの責務にして、セキュリティ上のリスクをおさえるため。 また、PodはevictionとかによってAdmiraltyの知らないところで消えたりもするので、より安定なPodChaperonを介することでAdmiraltyが制御を失わないようにする目的もある。
図ではPodのことしか書いてないけど、Source Podが依存するConfigMapやSecret、Podに紐づくServiceやIngressもしっかりターゲットクラスタにコピーされ、Delegate Podに紐づけられる。
また、Source Podに対するkubectl logsやkubectl execもDelegate Podにフォワードされて期待通りに動く。
Admiraltyをためす
二つのクラスタをAdmiraltyでつなげて、簡単なJobを実行してみる。
環境
ためす環境は、前々回の記事で作った、Kubernetes 1.21.2とk3s 1.21.2による以下のようなもの。
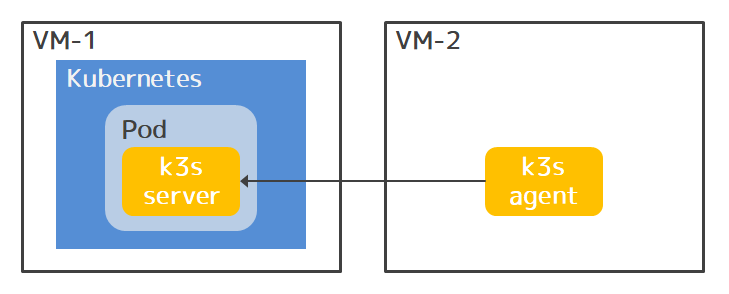
k3sクラスタのマスタ(i.e. k3s server)がKubernetesクラスタのPodで動いていて、別マシンがk3sクラスタのノードになっている。
Kubernetesクラスタをソースクラスタ、k3sクラスタをターゲットクラスタとする。
ソースクラスタへのAdmiraltyインストール
まずソースクラスタにAdmiraltyをインストールしたいんだけど、Admiraltyは前述のMutating Pod Admission Webhook(とか)のAdmission WebhookをHTTPSで動かすので、そのTLSサーバ証明書が必要で、Admiraltyの公式インストール手順ではそれをcert-managerに作らせるようになっているので、とりあえずcert-managerを入れる。
[root@vm-1 ~]# kubectl apply -f https://github.com/jetstack/cert-manager/releases/download/v1.6.1/cert-manager.yaml
[root@vm-1 ~]# kubectl get po -n cert-manager
NAME READY STATUS RESTARTS AGE
cert-manager-55658cdf68-bbcnf 1/1 Running 0 5m3s
cert-manager-cainjector-967788869-dwl5z 1/1 Running 0 5m3s
cert-manager-webhook-6668fbb57d-m5nlv 1/1 Running 0 5m3scert-managerがソースクラスタで動いた。 因みにcert-managerは、TLS証明書をKubernetsのカスタムリソースで管理できるオペレータで、IssuerでLet’s Encryptとかの証明書発行者を登録しておいて、Certificateを登録すると、CertificateRequestを作って実際にその発行者にCRを投げて証明書を取得し、それを格納したSecretをCertificateに紐づけてくれたり、特定のアノテーションをつけたWebhookConfiguration(とか)にCA証明書を挿入してくれたりする。
本題に戻って、ソースクラスタにAdmiraltyをいれる。 いれるのはv0.14.1。
GitHubにあるHelm Chartを取得。
[root@vm-1 ~]# git clone https://github.com/admiraltyio/admiralty.git
[root@vm-1 ~]# cd admiralty/charts/multicluster-scheduler/
[root@vm-1 multicluster-scheduler]# git checkout v0.14.1CRDを先にいれる。
[root@vm-1 multicluster-scheduler]# find crds/ -name "*.yaml" | xargs -I {} kubectl apply -f {}公式の手順ではhelm installするんだけど、なんとなくhelm templateでマニフェストをレンダリングしてapplyしたいので、Chart Hookを消しておく。
[root@vm-1 multicluster-scheduler]# rm -rf templates/post-delete/IssuerとCertificateのAPIバージョンが古いので直す。 あとVMのリソースの都合でレプリカ数を減らす。
[root@vm-1 multicluster-scheduler]# sed -i -e "s/v1alpha2/v1/" templates/issuer.yaml
[root@vm-1 multicluster-scheduler]# sed -i -e "s/v1alpha2/v1/" templates/cert.yaml
[root@vm-1 multicluster-scheduler]# sed -i -e "s/replicas: 2/replicas: 1/" values.yamlapply。
[root@vm-1 multicluster-scheduler]# helm template --name-template hoge . | kubectl apply -f -
[root@vm-1 multicluster-scheduler]# kubectl get po
NAME READY STATUS RESTARTS AGE
hoge-multicluster-scheduler-candidate-scheduler-7994c546d8cnm29 1/1 Running 0 22m
hoge-multicluster-scheduler-controller-manager-788dc65475-c764x 1/1 Running 0 22m
hoge-multicluster-scheduler-proxy-scheduler-8457f5f655-tzt6n 1/1 Running 0 22m
hoge-multicluster-scheduler-restarter-544df48444-k5cwv 1/1 Running 0 22m
k3s-57d95d5c47-sdzpl 1/1 Running 0 45hこれでソースクラスタでAdmiraltyが動いた。 candidate-schedulerが無駄に動いているのと、scheduler-restarterってなんだっけというのはあるけど、気にしない。
ターゲットクラスタへのAdmiraltyインストール
次にターゲットクラスタであるk3sクラスタにAdmiraltyを入れる。
大抵はターゲットクラスタでもソースクラスタと全く同じことをすればいいんだけど、今回の環境ではk3sのマスタ(i.e. k3s server)がPodで動いていて、別マシンのノード上で動くPodへの疎通がないので、ちょっと工夫が必要。
つまり、cert-managerとAdmiraltyをk3sクラスタに入れると、それらのWebhookサーバのPodがVM-2上で動くわけだけど、k3sクラスタのkube-apiserverはVM-1のPod内で動いていて、Webhookサーバに割り当てられたCluster IPと通信できないのでWebhookを実行できない、という問題を回避する必要がある。
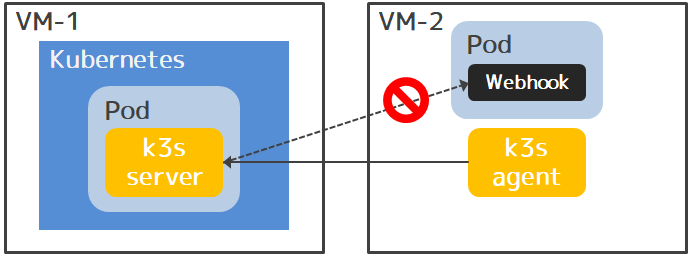
ここでよく考えると、上記「Admiraltyの仕組み」で見たように、AdmiraltyのMutating Admission Webhookはソースクラスタでだけ使われるものなので、k3s側にはそもそも要らない。 Admiraltyが動かすWebhookは他にも、カスタムリソースのValidating AdmissionWebhookとCustomResource Conversion Webhookがあるんだけど、前者はカスタムリソースの登録・変更時にバリデーションするだけなので無くてもいいし、後者もカスタムリソースのAPIバージョンを複数サポートしたい場合に使うものなので要らない。
cert-managerはAdmiraltyのWebhookの証明書を管理する用なので、Webhookが要らないならcert-manager自体要らない。
というわけでそれらを除いてインストールする。 k3sクラスタへは、VM-1上で動くk3s server Podの中からkubeconfigを取り出してkubectlに渡せば接続できる。
[root@vm-1 multicluster-scheduler]# kubectl exec -it k3s-57d95d5c47-sdzpl -- /var/lib/rancher/k3s/data/57d64d4b123cea8e276484f00ab3dfa7178a00a35368aa6b43df3e3bd8ce032d/bin/cat /etc/rancher/k3s/k3s.yaml > /tmp/k3s.yaml
[root@vm-1 multicluster-scheduler]# sed -e "s/127.0.0.1/$(hostname -i)/" -i /tmp/k3s.yaml
[root@vm-1 multicluster-scheduler]# kubectl --kubeconfig /tmp/k3s.yaml get node
NAME STATUS ROLES AGE VERSION
vm-2.local Ready <none> 45h v1.21.5+k3s2cert-managerは要らないのでスキップ。
AdmiraltyのChartからは、cert-managerのCR(i.e. IssureとCertificate)と、WebhookConfigurationを消しておく。
[root@vm-1 multicluster-scheduler]# rm -f templates/cert.yaml templates/issuer.yaml templates/webhook.yamlcert-managerがCertificateに対して作るSecretはAdmiraltyのWebhookサーバがマウントして使うんだけど、cert-managerを入れてないのでそのSecretが作られない一方、Webhookサーバはmulticluster-scheduler-controller-manager Pod(i.e. multicluster-scheduler-agentプロセス)に他の必要なコントローラとごった煮になってて止められないので、multicluster-scheduler-controller-managerがSecretのマウントに失敗して落ちないように適当なSecretを作っておく。
ソースクラスタからCertificateのSecretを持ってきて名前だけ変えればいい。
[root@vm-1 multicluster-scheduler]# kubectl get secret hoge-multicluster-scheduler-cert -o yaml > /tmp/cert.yaml
[root@vm-1 multicluster-scheduler]# sed -e 's/hoge-multicluster-scheduler-cert/foo-multicluster-scheduler-cert/' -i /tmp/cert.yaml
[root@vm-1 multicluster-scheduler]# kubectl --kubeconfig /tmp/k3s.yaml apply -f /tmp/cert.yamlAdmiraltyをインストール。
[root@vm-1 multicluster-scheduler]# find crds/ -name "*.yaml" | xargs -I {} kubectl --kubeconfig /tmp/k3s.yaml apply -f {}
[root@vm-1 multicluster-scheduler]# helm template --name-template foo . | kubectl --kubeconfig /tmp/k3s.yaml apply -f -
[root@vm-1 multicluster-scheduler]# kubectl --kubeconfig /tmp/k3s.yaml get po
NAME READY STATUS RESTARTS AGE
foo-multicluster-scheduler-controller-manager-788dc65475-lwgbc 1/1 Running 0 96s
foo-multicluster-scheduler-candidate-scheduler-7994c546d89dggc 1/1 Running 0 96s
foo-multicluster-scheduler-proxy-scheduler-8457f5f655-g6f7s 1/1 Running 0 96s
foo-multicluster-scheduler-restarter-544df48444-7dzpx 1/1 Running 0 96sターゲットクラスタでもAdmiraltyが動いた。
Admiraltyの設定
次に、Admiraltyの設定として、ソースクラスタにターゲットクラスタを、ターゲットクラスタにソースクラスタを登録する。 それぞれTarget、SourceというCRを使う。
Targetには、ターゲットクラスタに接続するためのkubeconfigをいれたSecretを指定する。 本当は権限を絞ったServiceAccountで接続する、専用のkubeconfigを作らないとセキュリティ的にダメなんだけど、簡便にさっきk3s server Podの中から取り出したkubeconfigを使う。
[root@vm-1 ~]# kubectl create secret generic k3s-kubeconfig --from-literal=config="$(cat /tmp/k3s.yaml)"
[root@vm-1 ~]# cat <<EOF | kubectl apply -f -
apiVersion: multicluster.admiralty.io/v1alpha1
kind: Target
metadata:
name: k3s
spec:
kubeconfigSecret:
name: k3s-kubeconfig
EOFSourceには、ソースクラスタからの接続を認可するServiceAccountを指定する。
k3s server Podの中から取り出したkubeconfigのServiceAccount名はdefaultなので、それを指定して登録する。
[root@vm-1 ~]# cat <<EOF | kubectl --kubeconfig /tmp/k3s.yaml apply -f -
apiVersion: multicluster.admiralty.io/v1alpha1
kind: Source
metadata:
name: k8s
spec:
serviceAccountName: default
EOF
[root@vm-1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
admiralty-default-k3s Ready cluster 163m
vm-1.local Ready <none> 125d v1.21.2Admiraltyによる仮想ノードであるadmiralty-default-k3sがソースクラスタに追加された。
最後の設定として、Admiraltyによる仮想ノードへのスケジューリングを有効にするnamespaceを指定するため、namespaceにmulticluster-scheduler=enabledというラベルを付ける。
今回はdefault。
[root@vm-1 ~]# kubectl label ns default multicluster-scheduler=enabled仮想ノードへのPodのデプロイ
仮想ノードにPodをスケジューリングしてもらうには、multicluster-scheduler=enabledを付けたnamespaceに、multicluster.admiralty.io/elect: ""というアノテーションを付けたPodを作ればいい。
今回はJobを使って、echoしたあとsleepするPodを作る。
[root@vm-1 ~]# cat <<EOF | kubectl apply -f -
apiVersion: batch/v1
kind: Job
metadata:
name: test
spec:
template:
metadata:
annotations:
multicluster.admiralty.io/elect: ""
spec:
containers:
- name: c
image: busybox
command: ["sh", "-c", "echo hogeeeee && sleep 100"]
restartPolicy: Never
EOF
[root@vm-1 ~]# kubectl get po -o "custom-columns=NAME:.metadata.name,NODE:.spec.nodeName"
NAME NODE
hoge-multicluster-scheduler-candidate-scheduler-7994c546d8cnm29 vm-1.local
hoge-multicluster-scheduler-controller-manager-56b5fcf8db-5jrdn vm-1.local
hoge-multicluster-scheduler-proxy-scheduler-855d6654f-gkscp vm-1.local
hoge-multicluster-scheduler-restarter-544df48444-k5cwv vm-1.local
k3s-57d95d5c47-sdzpl vm-1.local
test-cz5mp admiralty-default-k3s登録したJobから作られたPodのtest-cz5mpが、仮想ノードのadmiralty-default-k3sにスケジューリングされた。
[root@vm-1 ~]# ps aux | grep -e '[s]leep'
[root@vm-1 ~]#ソースクラスタのノード(i.e. VM-1)上でsleepプロセスは動いていない。
[root@vm-1 ~]# kubectl get po --kubeconfig /tmp/k3s.yaml
NAME READY STATUS RESTARTS AGE
foo-multicluster-scheduler-candidate-scheduler-7994c546d89dggc 1/1 Running 2 7h11m
foo-multicluster-scheduler-proxy-scheduler-8457f5f655-g6f7s 1/1 Running 2 7h11m
foo-multicluster-scheduler-restarter-544df48444-7dzpx 1/1 Running 4 7h11m
foo-multicluster-scheduler-controller-manager-788dc65475-lwgbc 1/1 Running 4 7h11m
test-cz5mp 1/1 Running 0 55sターゲットクラスタでtest-cz5mpが動いている。
[root@vm-2 ~]# ps aux | grep -e '[s]leep'
root 56450 1.4 0.0 1300 4 ? Ss 18:27 0:00 sleep 100ターゲットクラスタのノード(i.e. VM-2)上でsleepプロセスがちゃんと動いている。
[root@vm-1 ~]# kubectl logs test-cz5mp
hogeeeeeソースクラスタのtest-cz5mpに対してkubectl logsもできることが確認できた。